What I learnt from DSTA's BrainHack [Computer Vision]
- Nicole Seah
- Jul 18, 2021
- 5 min read

A few weeks ago, my friends and I participated in DSTA's hackathon for machine learning - they had tasks for both computer vision and sound classification. Since the epochs took a really long time to load, we had to split the workload and I was more focused on improving the accuracy of our computer vision model.
The dataset and problem provided revolved around classifying animals, from cats to dinosaurs. There were a total of 6 tasks, 3 for computer vision and 3 for sound classification. We could only move on to the next task if we hit the minimum accuracy required. Being totally new to deep learning, we only managed to complete 4 out of 6 of the tasks within the 2-day hackathon. However, it was still a really good learning experience and I hope to share what little basic knowledge I have gained which could help other newbies when they approach their first deep learning project - something of a little cheatsheet I wish I came across when I first had to dive right into the hackathon.
While DSTA did provide some tutorials on deep learning, I felt like they focused a lot on concepts and provided little insight on what we actually had to do for the task itself. For example, the concepts covered in the tutorials were on machine learning architectures and they had already provided us with a ready-to-use model in an ipynb notebook. I understand that it is (of course) good to know how a machine learns, however, from what I read online (especially for beginners), people conducting data analysis usually rely on ready-made machine learning architectures and rarely alter them/create one from scratch for their own use. Hence, since we didn't really have to edit the architecture of the machine learning model, we didn't know what else we had to do at the beginning as the videos provided didn't cover anything else.
Learning Points
So, here is what I learnt about how to improve the accuracy of a machine learning model as a TOTAL beginner and I'm going to use SUPER basic terms. Also, a small disclaimer that I am not here to explain code, but rather answer questions I had while I was doing the project myself. I found that Tech with Tim's videos on neural networks helped lay a foundation for this project, hence the information I will be sharing below is an add-on to what he has already covered in his video tutorial. I have also provided several links which explain the concepts in more detail.
What is Torchvision used for?
It is used to modify features and labels by transforming images into the required format so that they can be used as input data for the model.
How are images stored as data?
Image arrays are 3D - they consist of 3 'layers' of RGB (Red, Green, Blue)
What are the different types of neural networks and when should we use them?
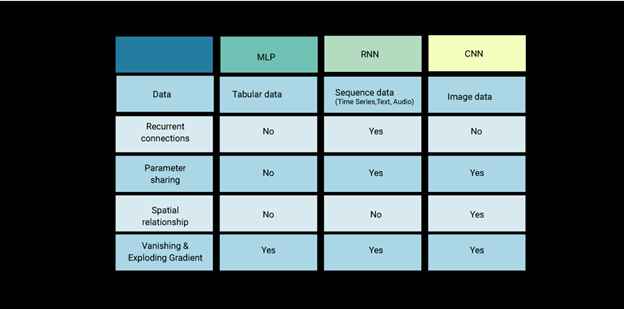
MLP is also known as ANN (Artificial Neural Networks) which is used for computer vision as it processes multilayer data - ie a 3D array that represents an image. ANN takes in a vector input.
CNN is also used for computer vision but it takes in a tensor rather than a vector (as compared to ANN). This is more commonly used today and is much better at classifying images as compared to the outdated ANN.
RNN is used for sound classification since it takes in sequence data.
What are activation functions?

Activation functions are used to define the output of a node (ie whether something is X or Y).
What are optimizers?
Optimizers are formulas that changes the weights to reduce errors (weights are what determines the output, ie shows the significance of one variable over the other when making a decision/prediction).
We used 'learning rate' as a hyperparameter to tune the optimizer. Learning Rate is how big of a step the algorithm can take, should not be too large (might step over global minimum) or small. You can use a learning rate schedule to modulate how the learning rate of your optimizer changes over time.
The intuition behind this approach is that we'd like to traverse quickly from the initial parameters to a range of "good" parameter values but then we'd like a learning rate small enough that we can explore the "deeper, but narrower parts of the loss function" (from Karparthy's CS231n notes).

What are some points to take note of in image processing?
Tensors come in this format (Height, Width, Channels). We need to divide the data by 255 to allow the model to learn faster.
Some data augmentation methods include: Mirroring, Cropping, Blur/Sharpen Filter, Kernel, Rotations, Colour transformation, Changing textures, Deformations. More can be found here: https://nanonets.com/blog/data-augmentation-how-to-use-deep-learning-when-you-have-limited-data-part-2/, https://www.tensorflow.org/tutorials/images/data_augmentation
Specifically for CNN, it takes in
Kernel Weights
Pooling layers (max intensity value of pixel with a given subpart of the image) reduces cost of training and over-learning of data
Dropout layer - Prevent model from over-learning data, entirely random with no assumptions
Striding – taking average of a few blocks to form smaller pixel images
Padding – adds white spaces at ends of the image and increases the importance of the borders
Dilation – skips a few pixels to increase global view
CNN takes a long time, hence R-CNN, Fast R-CNN and Faster R-CNN have been used for image classification. Read more here: https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
What is the difference between Resnet variants?
Resnet is used as the backbone for the machine learning architecture in this project. A few variants are: Resnet50, Resnet101, Resnet152.
I wish someone could explain it better to me still, but what I gathered was that higher Resnet numbers are more complex and also take up a longer time for model training. I will definitely have to revisit this concept next time.
What did we ACTUALLY have to do for the project?
Change the hyperparameters: which layer resnet to use, number of epochs, the learning rate, the IoU threshold and the batch size. As a beginner, we felt that it was really just a trial-and-error to see which combination of hyperparameters worked the best to provide the highest accuracy. Each time we trained the model, it took approximately 1h to 1h30min for round 4000 images. Hence, I don't think I am able to recommend a specific set of values to use for each hyperparameter.
Things we could have done better?
Created more data points through data augmentation - we tried to do this but our code didn't work at all. I had visited a few websites to get their code but nothing was working...
Ask for help from someone with more experience - our whole group had no experience in machine learning and we were really just lost sheep for the entirety of the hackathon. I really wish I had a better idea of what was going on for each step in the code they had provided us.
Closing statements
Overall, it was still a really good learning experience since this is something I had not done ever and at least I left the hackathon with a bit more knowledge than I had before starting the project - I see this as an absolute win! My advice: machine learning is definitely not something that can be learnt overnight, so definitely get some help from someone who is more experienced than you so that you are able to learn better!


Comments